There is no way to predict what AI will look like by the end of 2024, period.
What we know for sure is that it will be more powerful and cheaper than what it is now.
Luckily, the Law of Scaling Large Language Models (LLMs) makes it relatively easy to help us predict that performance because it distills the model efficacy to two key factors: computing power (aka $$$) and data. The more computing power you throw at the problem and the more data (and higher quality) you throw at it, the better the model becomes. We’ve yet to observe a plateau in this curve, indicating that increased compute and data inputs consistently enhance model performance.

The race for the best model continues; as such, we can guess what the focus area for AGI labs will be in 2024.
They will also be cheaper, both in training and inference. It is mainly fueled by the open-source efforts of companies such as Mixtral and (partly) Llama and the whole open-source community.
This post delves into the four key levers that enhance performance and increase efficiency. I set aside the crucial topics of alignment and security for a detailed discussion in a subsequent post.
More powerful models
Size Matters…
The influx of investment into the AI sector signifies no shortage of funds for companies pouring billions into computing power and announcing larger and larger models (Inflection). This is paving the way for models with trillions of parameters, dwarfing the likes of GPT-3’s 120B and Llama’s 70B parameters. In 2024, we’re poised to witness the debut of some huge models.

…But Quality Matters More…
Recent strides in efficient modeling have shown that the real game-changer for the scaling law curve is high-quality, easily digestible data. This type of data has already brought about significant improvements. A prime example is Microsoft’s Phi2 model, which boasts a staggering 25X (Phi-2) performance boost per unit of energy, thanks primarily to better-structured data.
If this trend continues, 2024 could see a surge in small, highly efficient models driving applications that demand heavy inference but don’t necessarily require state-of-the-art (SOTA) results.
BUT (and this is a big ‘but’), the wonders of data don’t end there. The real magic begins when we introduce high-quality synthetic data from other powerful models into the training process (Microsoft Research paper). When combined with post-training optimizations (more on this later), we’re essentially entering the second phase of an ‘Alpha Go’ scenario (Karpathy’s explanation of this idea and its challenges). We’re talking about using advanced data beyond our current understanding to train models, paving the way for rapid scientific advancement.
… especially when you start to mix modalities …
One final line of work related to the high-quality data trend is multimodality. Models are now being built from the ground up (i.e., Gemini) to be multimodal (receive the description of a website with a voice memo and an image, respond with code and image to illustrate it). What does “from the ground up” mean? It means there’s no need to use modality-transition models (e.g., Whisper) to switch between modalities, increasing the quality of the result (i.e., models will start understanding the tone of your voice, which is super important in human conversations)
Data and power still leaves room for breakthrough architectures
With significant investments in both funding and data, another way to shift the Law of Scaling curve or address some of the most burning problems is through algorithmic and architectural breakthroughs (think Q*). Two challenges are currently being heavily targeted: context length and energy consumption.
New algorithmic improvements are more secretive, and thus I am sure I am behind the latest knowledge in the AGI labs, but two trends are emerging.
- Long Context Problem: Enter Mamba (less technical explanation), a rising star designed to tackle long context issues. Current AI models struggle with retaining information from earlier in a conversation. Mamba aims to manage complex interactions between input tokens, enabling longer context understanding than ever before. This is significant, as it means AI can now process extended conversations or documents, a feat that was previously challenging.
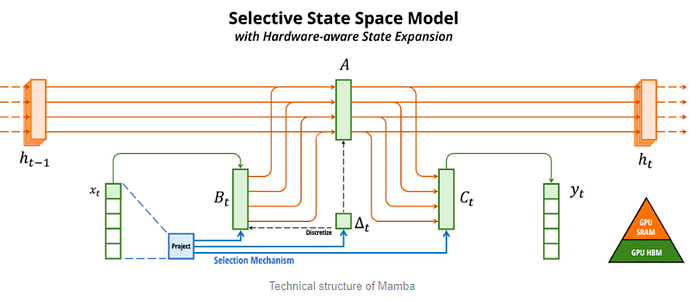
Efficient Parameter Usage: Then there’s MoE (Mixture of Experts), which focuses on energy-smart operation. It activates only specific parts of the model as needed, akin to calling in an expert from a team of specialists for their unique skills. GPT-4 is considered one MoE (George Hotz’s podcast), but the guys team brought this to the light are the Mixtral team.
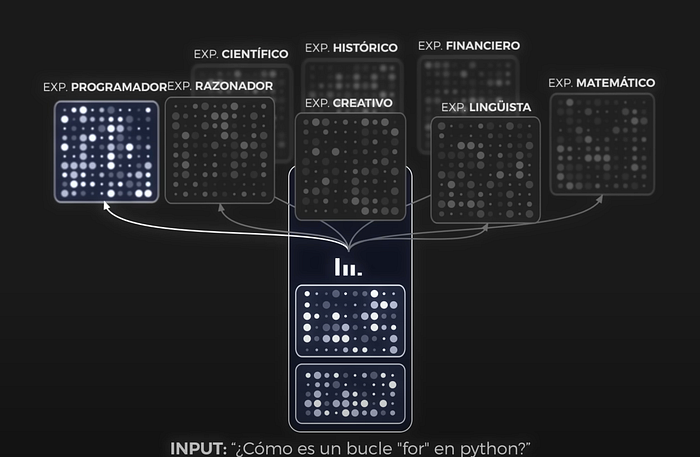
And don’t forget the Untapped Potential of Post-Training Optimizations
Imagine you have a fancy 2000T parameter model. Initial tests are impressive, but we’re beginning to understand that these tests only scratch the surface of the model’s capabilities (and that’s now that the model still produces solutions we understand!).
Numerous, often cost-effective, post-training optimizations can elevate the same model to new heights. Think of these like fine-tuning a sports car for enhanced performance (like switching to wet tires on a rainy day).
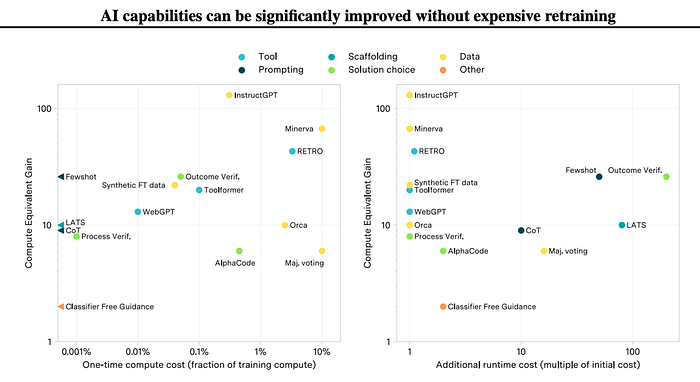
Among these optimizations, the most promising is allowing models more time to ‘think’. A well-known method for this is Chain of Thought (CoT). CoT instructs the model to take its time, articulate its thought process, and solve the problem.
The results are extraordinary when combined with step-by-step verification (using another LLM to analyze each step). Leveraging current technology and applying variations of this concept, Google researchers have improved solutions for mathematical optimization problems previously unsolved (hinting at new beyond-human-level data for the model — you see the connection?).
On the frontier, we’re exploring models that can autonomously decide when to utilize more or less computing power. Think of Mixtral on steroids (more on this soon). Whether attempting to solve the Riemann Hypothesis or developing a new cancer drug, the cost becomes a secondary concern in pursuing groundbreaking results.

As explained in We Are Not Lazy, We Play Smart, we will continue to hyper-focus on understanding and solving our users’ needs, relentlessly working to pass the improvements to our users in a scaled way. We will experiment as early as the research is released, we will move to production as soon as our users can benefit of it in an scalable way
Oh yeah, 2024 is going to be fun.